DBmasker ANO syntax
Creating the ANO file
The DBmasker service takes one input: the ANO file, which contains the data schema information and the rules you write. In the following is the ANO syntax described in a simplified EBNF based railroad diagrams. Three symbols are used:
|
|
A terminal representing plain text written as given in the box. |
|
|
A box with small letters. A nonterminal representing a reference to another syntax diagam |
|
|
A box with only capital letters. A nonterminal representing parameters/values as defined by the name. |
The model
The ANO file contains three sections:
-
database schema information
-
user defined classes
-
tasks and rules
model
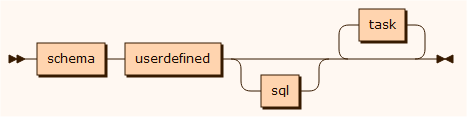
The schema section
The schema section defines the database structure in a simplified syntax:
A sample schema section:
table CUSTOMER column integer CUSTOMERNO column text NAME size 40 column text CREDITCARD column text EMAIL column text PASSWORD column text PHONE column integer CUSTODIAN primary-key CUSTOMERNO unique NAMEINDEX NAMEtable INVOICE column integer INVOICENO column text INVOICETEXT column decimal VALUE size 20 scale 2 column integer CUSTOMER_CUSTOMERNO primary-key INVOICENOforeign-key INVOICE CUSTOMER_CUSTOMERNO CUSTOMER CUSTOMERNOThe schema part is simplified SQL statements. You may convert SQL schema files to the ANO form by using the DBano service, which takes SQL as input and delivers an equivalent ANO file. The syntax is described as follows:
schema

The TABLE and COLUMN non-terminals represent a table and a column name.
type
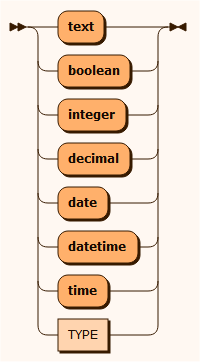
The TYPE non-terminal represents some type value not covered by standard types.
size
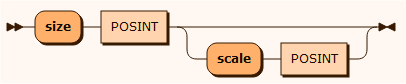
The column size is given by the size POSINT value and the scale on decimal numbers is given by the scale POSINT where POSINT is a positive integer.
pk
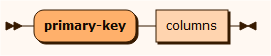
unique

INDEX-NAME is the name of the index.
fk
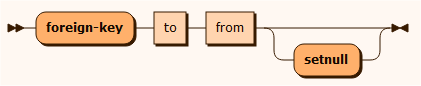
The setnull terminal indicates that the association represented by the foreign key, may exist.
columns
to/from
The user defined classes section
Some masking parts use functions to manipulate values and add rows to the database and you may create user defined specialized classes (All interfaces and abstract classes are explained in the javadoc):
|
Package |
Description |
|
conversions |
Package containing custom conversion classes. Defined for randomized or masked columns using a column input source. Converts input strings into another string format or can convert string into another data type for randomized columns. Implements no.esito.anonymizer.IConversion interface. Built in conversions used for converting string input to various other data types:
|
|
distributions |
Package containing custom distribution classes. Defined for dependent tables when creating data for tables. Used for determining the distribution of foreign keys between the parent and child tables. Implements no.esito.anonymizer.IDistribution interface. Distributions may have two parameter definitions:
Built in distributions:
|
|
transformations |
Package containing custom transformation classes. Defined for masked columns. Used to transform column value before being written to the database. (See ReplaceDigits.java in AnonymizerHotel example). Implements no.esito.anonymizer.ITransformation interface. Built in transformations:
|
The built-in classes have no.esito.anonymizer.conversions, no.esito.anonymizer.distributions and no.esito.anonymizer.transformations packages. All built-ins are implicitly defined.
Sample classes part:
conversion example.anonymizer.conversions.ParseDigitstransformation example.anonymizer.transformations.PostCodeGeneralizationdistribution example.anonymizer.distributions.MinPerParentuserdefined

The CLASS represents a user defined class with full java package specification.
The tasks and rules section
A Task is either a TaskGroup or a WorkTask. TaskGroups can have infinite child tasks of both kinds while WorkTasks only contain rules. A WorkTask is one of update, create, delete, erase or sar. Naming tasks follow these rules:
-
Group tasks names must be unique while work task names must be unique within a group task
-
Group tasks on the same level in the task hierarchy must have unique names
-
Work tasks on the same level in the task hierarchy must have unique names
-
Group tasks cannot have the same name as any of the work tasks it contains. If the work task does not have an explicit defined name it is the default name that is forbidden, i.e. the work task Delete HOTEL gets by default the name Delete_HOTEL
-
The name comparison is case insensitive to prevent file name collisions on case insensitive file systems
Running TaskGroups, will run all child tasks in defined sequence. Running WorkTasks, will run all tasks with same name regardless of which TaskGroup they belong and in the sequence they are defined.
We will often use the common phrase task both for TaskGroup and WorkTask.
A TaskGroup contains tasks which can be both TaskGroups and WorkTasks. The purpose is to group tasks as an entity.
A WorkTask is one of
-
update - mask and make data unrecognizable
-
delete - sub setting database to reduce size
-
create - create records for testing
-
erase - remove obsolete data
-
sar - create reports from database
A Rule defines anonymizations/masking on data and consists of
-
mask - anonymize data
-
randomize - add noise to numbers
-
shuffle - reorder data sequence
WorkTasks are detailed by Rules.
Through out of this documentation, we will be using the phrases taskgroup and worktask, or the common task.
The example below consists of two tasks: Anonymize (taskgroup) and update_CUSTOMER (worktask) and two masking rules for NAME and EMAIL.
// Pure Anonymizationstask Anonymize { // Anonymize - Mask various Customer fields update CUSTOMER // Create random name from list of firstnames and lastnames mask NAME format "%s %s" file src/main/resources/firstname.txt random-order file src/main/resources/lastname.txt random-order // Create email based on the newly created name mask EMAIL format %s@%s transform Email // Use built-in transformation class unique column NAME file src/main/resources/email.txt random-order}Creating Tasks
A task is one of
|
task |
A combination of tasks, both taskgroups and worktasks. |
|
update |
Updates or Anonymizations are organized by table and performed on one or more of its columns and on columns from dependent tables (i.e. foreign keys). The table anonymizations are organized by task and the table anonymization node contains separate child nodes for each column that is to be anonymized. |
|
create |
In test and development environments it is often necessary to work with various test data for developing and testing different scenarios. With Create data for Table, you can insert rows into database tables with sample data and also create records for child tables that are linked together by foreign keys. It is important to define the creation of data for parent tables before defining the creation of data for the child tables and then ensure that the relation via the foreign keys are defined. You can use the masking to assign data to the columns and if you are using an external file for the data source and you don't select the random order option, the tasks can be constructed so that the database contains the exact same data each time the tasks are run. You can also specify the distribution of foreign keys used in child records by specifying one of the various distribution algorithms supplied or you can create a customized distribution for your own purposes. If a parent table is referenced by many child foreign keys, a distribution algorithm may be defined for a group of child tables. |
|
delete |
When creating a test or development environment, it is often necessary to perform a full copy of the production database in order to acquire a proper data set. This may result in a data set that is too large and unmanageable, often requiring an analysis of the data content and structure to delete data in order to shrink the database size. This is often called database subsetting. When determining the records that need to be deleted, it is important to understand the structure so that the correct table data deletion sequence is followed. However, if the database has proper foreign key definitions, dbMasker can facilitate the process of establishing all dependent tables. Start with tables that have no parent tables and decide on which data in the tables to delete. All dependent data in dependent tables following the foreign key structure, will also be automatically marked for deletion. You may remove any dependency or manually add dependencies on other tables. |
|
erase |
The erase task allows you to combine anonymizations (masking) and deletions.This may be used to anonymize or remove obsolete data. It may also be used to support GDPR §17 The right to Erasure or Right to be forgotten in GDPR or other privacy regulations. It may also help with consent withdrawal related to GDPR §7 . |
|
sar |
A subject access request (SAR) is a concept in GDPR that describes requests by individuals to an organization to see copies of all information that relates to them. This includes any personal data and reasons for its use.The sar task allows you to output information stored about an individual into multiple source files supporting a JavaScript Object Notation (JSON) format and XML format. These source files can be used by various readers to provide the requested information. This gives the user a way to verify data correctness and if necessary request corrections or deletions of personal information. |
task
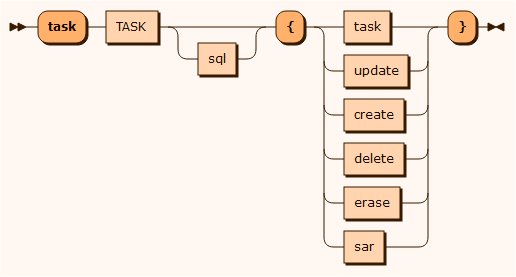
The TASK represents a task name and sql represents SQL statements run before and after the task defined operations.
The update, create, delete, erase and sar are all worktasks and may be run as a task with the implicit name given by the task type and the TABLE name as in "update_CUSTOMER". A NAME may be given and it will override the implicit name.
sql

The SQL represents complete SQL statements. The statement must be written inside double quotes ("statement”) and any occurrences of double quotes or backslash must be escaped with a backslash: \" and \\. There will be no check of SQL syntax and a statement cannot be divided on serveral lines. Multiple SQL statements may be written divided by newline .
update

Used for anonymizing/updating one or more columns for a specified table. Additional anonymization rules based on columns of the selected table may be added. See Creating masking/anonymization rules.
update ARTIST sql-before "delete from ARTIST where NAME is null" selection-key NAME orupdate ARTIST myTaskName sql-before "delete from ARTIST where NAME is null" selection-key NAME The first statement has no task name specification, giving the taskname update_ARTIST. The second sample specifies a task name, giving it the task name myTaskName.
create

In test and development environments it is often necessary to work with test data for developing and testing different scenarios. With create TABLE, you can insert rows into database tables with sample data and also create records for child tables that are linked together by foreign keys.
It is important to define the creation of data for parent tables before defining the creation of data for child tables and then ensure that the relation via the foreign keys are defined. Additional anonymization mask rules to assign data to the columns can be added and if you are using an external file for the data source and you don't select the random order option, the tasks can be constructed so that the database contains the exact same data each time the tasks are run.
You can also specify the distribution of foreign keys used in child records by specifying one of the various distribution algorithms supplied or you can create a customized distribution for your own purposes. If a parent table is referenced by many child foreign keys, a distribution algorithm may be defined for a group of child tables.
The minimum-rows POSINT value ensures that the table will have at least minimum-rows records inserted.
distribute

The DISTRIBUTION denotes an algorithm that ensures consistency between parent and child tables via foreign keys. The class must implement the IDistribution interface.
The DISTRIBUTION class can be one of the built-in classes or defined in the user defined distribution classes section. The sample below uses the built-in class AllCombinations. It ensures that all possible combinations of ROOM rows connected to HOTEL and ROOMCATEGORY are created.
create ROOM minimum-rows 50 mask ROOMNO format %d random-integer 101 399 mask BALCONY format %d random-integer 0 1 mask ID format %d unique sequence -1 1 // Every hotel should have a room of each category distribute AllCombinations "" //Use built-in distribution class table ROOMCATEGORY "" child CATEGORY_ID parent ID table HOTEL "" child HOTEL_ID parent IDdelete

Used for deleting a sub-set of data from a specified table and records from referenced tables. Cascading deletes of dependent tables is supported and shown in the sample code below.
The 3 cascading delete methods have different performance of deleting a hierarchy of records. The characteristics are:
-
cascading
-
Children are deleted first, and the parent last
-
Generally works without disabling constraints
-
Slow performance (one by one)
-
-
not-exists
-
Parent is deleted first
-
DELETE FROM parent WHERE XX
-
-
Thereafter all orphans are deleted using
-
DELETE FROM child WHERE NOT EXISTS (SELECT * FROM parent WHERE parent.id = child.parent_id)
-
-
Fastest, but constraints must be disabled
-
-
not-in
-
Parent is deleted first
-
Thereafter all orphans are deleted using
-
WHERE child.parent_id NOT IN (SELECT DISTINCT parent.id FROM parent)
-
-
Fast, but constraints must be disabled
-
cascade
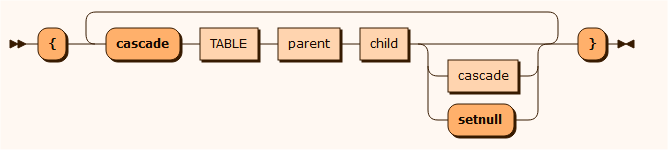
delete HOTELCHAIN where "ID = 0" { cascade HOTEL parent ID child CHAIN_ID { cascade BOOKING parent ID child HOTEL_ID { cascade STAY parent ID child BOOKING_ID { cascade NIGHT parent SERIALNO, CUSTOMER_CUSTOMERNO child STAY_SERIALNO, STAY_CUSTOMER_CUSTOMERNO } } }}erase

Used for erasing records in a table by anonymizing specified columns and deleting records from it's referenced tables, or masking specified columns in the referenced tables. It contains a parameterized condition bases on the selected tables primary key.
eraseTable

erase CUSTOMER where "CUSTOMERNO = %PARAMETER%" mask NAME format "firstname lastname" mask EMAIL format epost@email.com { // Anonymize identifiable columns cascade ADDRESS parent CUSTOMERNO child CUSTOMER_CUSTOMERNO mask HOMEADDRESS format "Home address" mask POSTALCODE format 1234 }simpleMask

sar

Used for creating data for Subject Access Requests reports. The exported data comes in the form of a xml or json file. It contains a parameterized condition bases on the selected tables primary key.
sarTable

sar CUSTOMER where "CUSTOMERNO = %PARAMETER%" mask CREDITCARD mask CUSTOMERNO mask EMAIL mask NAME { cascade STAY parent CUSTOMERNO child CUSTOMER_CUSTOMERNO mask SERIALNO mask BOOKING_ID mask INVOICE_INVOICENO mask LOCATION_ID { cascade NIGHT parent SERIALNO, CUSTOMER_CUSTOMERNO child STAY_SERIALNO, STAY_CUSTOMER_CUSTOMERNO mask ID mask DATE mask PRICE mask ROOM_ID } cascade BOOKING parent CUSTOMERNO child CUSTOMER_CUSTOMERNO mask FROMDATE mask TODATE mask ID mask HOTEL_ID }selectionKey

Possible selection keys are the primary key and unique indexes. The default selection key is the primary key defined for the table.
where
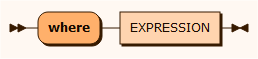
The EXPRESSION represents a logical expression. The expression must be written inside double quotes ("expression”) and any occurrences of double quotes or backslash must be escaped with a backslash: \" and \\.
The worktasks update, delete, erase and sar can all have a where clause defined to filter the data rows.
The worktasks delete, erase and sar can take values entered in a command or the API. This is defined in the where clause with the %PARAMETERn% notation. Note: You can use %PARAMETER% instead of %PARAMETER1%.
erase CUSTOMER where "CUSTOMERNO = %PARAMETER%" mask NAME format "firstname lastname" mask EMAIL format epost@email.comCommand use: erase customer 1000234erase COUNTRY where City = %PARAMETER1% AND country_id = (SELECT country_id FROM country WHERE country = %PARAMETER2%)Command use: erase country Paris Francechild
parent
Creating masking/anonymization rules
Anonymizations are organized by table and performed on one or more of its columns and on columns from dependent tables (i.e. foreign keys). The table anonymizations are organized by worktasks and the table anonymization statement contains separate statements for each column that is to be anonymized.
An anonymization rule is one of
|
mask |
The mask function masks the values of columns by replacing all or part of the data with generated values taken from various input sources. A mask may have several parameters based on one or more of the following:
|
||||||||
|
randomize |
The randomize function is used to apply noise on numeric and date column values. The algorithm is useful for hiding transactional data, whereby it maintains approximate values but changes it significantly so as to make it hard to recognize. |
||||||||
|
shuffle |
The shuffle function reorders the column values in a random order and ensures that no record retains the original column value. |
anonymization

The anonymization may get values from a mapping file, produce mapping to a file or both. A temporary value may be defined for columns that are primary keys or unique columns. It allows you to define a temporary key that is used to temporarily set as the value before the system reads through all records.
map
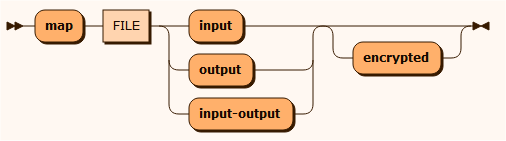
The map input function uses a mapping file containing key/value pairs (Key=Value) to update columns using the mapped value. The system reads the column value and checks if the mapping file has a corresponding key. If there is a key found, the column value is replaced with the mapped value. The mapping file is typically produced from another anonymizing rule using map output and could have originated in another database. With this function, it is possible to store the mapping values from one database, and apply those values to similar columns in another database. This ensures that both anonymized databases contain the same values.
The map output function produces a mapping file containing key/value pairs (Key=Value) from the anonymization rule.
The map input-output function uses the mapping file and produces the mapping file with key/value pairs (Key=Value), if there a new or missing values in the map file.
FILE is the file name and the content may be encrypted.
// Update primary key update COMPANY // Reuse masking from another database mask NAME map company_name.txt inputpropagate
// Update primary keyupdate INVOICE //Save the real and masked values on a file with encryption mask INVOICENO map "invoicemask.txt" output encrypted format %d unique sequence -1 1 propagate STAY.INVOICE_INVOICENO //Update foreign key alsoUse propagate to update foreign keys with the same value as the primary key mask and use map to update similar values in another database.
mask
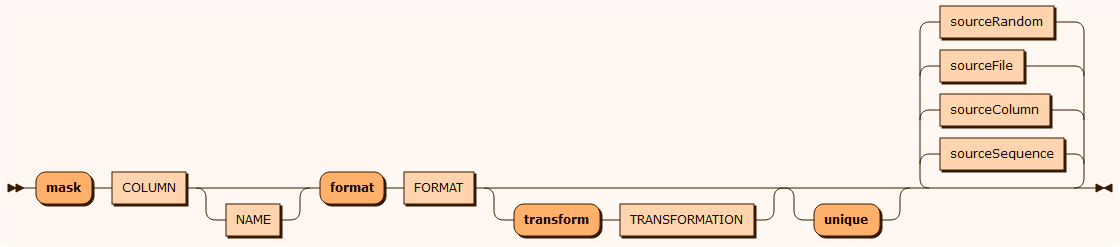
The mask function masks the values of columns by replacing all or part of the data with generated values taken from various input sources.
The FORMAT denotes the masking result and may be a combination of literal string values and format strings using java.util.Formatter. Use "" if there are spaces.
|
Format |
Input |
Description |
|
%s |
String |
Use with File and Column input |
|
%d |
Integer |
Use with Sequence and Random of Integer type |
|
%f |
Decimal |
Use with Randomization and Random of Decimal type |
|
%tF |
Date |
ISO 8601 formatted date "yyyy-MM-dd" |
|
%tT |
Time |
24-hour time format "HH:mm:ss" |
|
%1$tF %1$tT |
DateTime |
Database Timestamp format " yyyy-MM-dd HH:mm:ss " |
Without any format specifications the value is regarded as a constant. The text constant NULL is regarded as SQL NULL. Each format parameter must be mached with one of sourceRandom, sourceFile, sourceColumn or sourceSequence.
See more examples at https://dzone.com/articles/java-string-format-examples.
The transform TRANSFORMATION class is one of the classes defined in the user defined transformation classes section. The transform() method takes String as input and delivers a String object. The class must implement the ITransformation interface. See Email and CreditCard as samples below.
sourceSequence

The sequence input source is used to insert a sequence of integers into the column starting with the first INTEGER value and incremented by the second INTEGER value. If -1 is selected, the sequence starts with the highest value stored in the column plus the increment.
sourceColumn
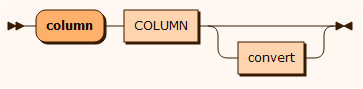
The column input source is used to insert the specified column value into the masked parent column. You can only specify a column from the same table. If the column being anonymized is not a string, you can use one of the conversions defined to convert the data type. See convert.
sourceFile

The file input source is used to insert a string value taken from the file defined in the FILE terminal. It picks a line from the file sequentially or randomly depending on the random-order property. A conversion class can be selected to manipulate the string selected from the text file. See convert.
sourceRandom
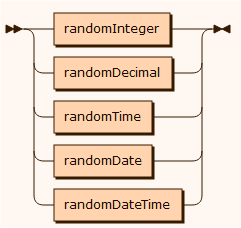
randomInteger

randomDecimal

randomTime

randomDate

randomDateTime

All the random-[type] input sources is used to insert a value drawn from a random sequence as defined by the first from value and the second to value.
The sample below shows anonymizations of a CUSTOMER table using all mask variants.
update CUSTOMER // Create random norwegian phone number mask PHONE format "+47 %d" random-integer 10001000 99909990 // Create random name from list of firstnames and lastnames mask NAME format "%s %s" file src/main/resources/firstname.txt random-order file src/main/resources/lastname.txt random-order // Create email based on the newly created name mask EMAIL format %s@%s transform Email unique column NAME file src/main/resources/email.txt random-order // Create random creditcard with checksum that validates mask CREDITCARD format 41428340%d transform CreditCard //Use the creditcard transformation class random-integer 10001000 99919991randomize
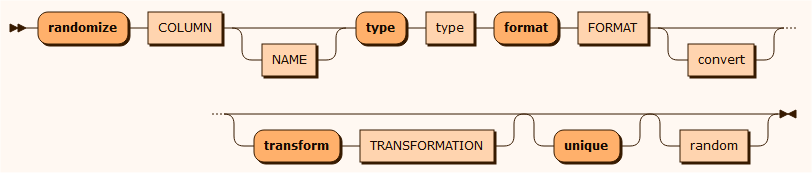
The randomize function is used to apply noise on numeric and date column values. The algorithm is useful for hiding transactional data, whereby it maintains approximate values but changes it significantly to make it hard to recognize. Supported types are Integer, Decimal, Date, Time and DateTime.
random

All input to the randomize function is read as a string. You must therefore specify a function to convert from the String type to the input type, defined by the type property:
|
Type |
Function |
Return type |
Expected format on string input |
|
Date |
String2Date |
java.time.LocalDate |
yyyy-MM-dd |
|
DateTime |
String2DateTime |
java.time.LocalDateTime |
yyyy-MM-dd HH:mm:ss |
|
Time |
String2Time |
java.time.Time |
HH:mm:ss |
|
Integer |
String2Integer |
java.lang.Integer |
Decimal integer with or without sign |
|
Decimal |
String2Decimal |
java.lang.Double |
Decimal number as accepted by the valueOf method in class Double |
|
Anonymization for types Integer, Decimal: |
|
|
FORMAT |
Printf format for the selected type: %d or %f |
|
Noise addition |
Grouping of various attributes that adds noise. Gaussian formula: |
|
flat-noise |
Adds a +/- Gaussian distributed noise with a deviation |
|
percentage-noise |
Adds a +/- Gaussian distributed noise with the magnitude as a percentage of the original value |
|
offset |
Adds a fixed offset to the value. |
|
Anonymization for types Date, DateTime |
|
|
FORMAT |
Printf format for the selected type: %tF or '%1$tF %1$tT' |
|
Noise addition |
Grouping of various attributes that adds noise. Gaussian formula: gaussian-distribution * flat-noise + offset |
|
flat-noise (days) |
Adds a +/- Gaussian distributed noise with a deviation |
|
offset (days) |
Adds a fixed number of days to the date value |
|
Anonymization for Type Time |
|
|
FORMAT |
Printf format for the selected type: %tT |
|
Noise addition |
Grouping of various attributes that adds noise. Gaussian formula: gaussian-distribution * flat-noise + offset |
|
flat-noise (seconds) |
Adds a +/- Gaussian distributed noise with a deviation |
|
offset (seconds) |
Adds a fixed number of seconds to the date value |
convert

The convert CONVERSION class is one of the built-in classes or defined in the user defined conversion classes section. The convert() method takes String as input and delivers an Object. The class must implement the IConversion interface. See String2Decimal sample below.
update ROOMCATEGORY // Add 1% gaussian noise to hide the value from search randomize INITIALPRICE decimal format %.2f convert String2Decimal offset 0.0 flat-noise 0.0 percentage-noise 1.0shuffle
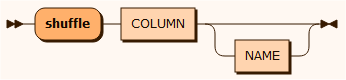
The shuffle function reorders the column values in a random order and ensures that no record retains the original column value.
update HOTEL // Output results to an encrypted file shuffle NAME map hotelmap.txt output encrypted //Write the mapping to a file, use encryption